LLM Research and Adaptation Landscape
The papers from this year’s major NLP/ML conferences (ACL, EMNLP, Neurips, ICML) indicate that community has pretty much accepted that Large Language Models (LLM) are here to stay. The paradigm has clearly shifted from one that is task or methods centric, to one that is model centric.

Training and Inference Pipelines
Since we have shifted to a pre-trained model paradigm, we can think of LLM work along two main pipelines,
- Improving Inference with the existing pretrained models.
- Further training, typically lightweight approaches if we’re not in LLM Shops.
Add-ons are related to both training and inference, but are mostly about making LLMs play-well with all sorts of data (tables), existing knowledge (graphs), and of course generation (fairness and other things).
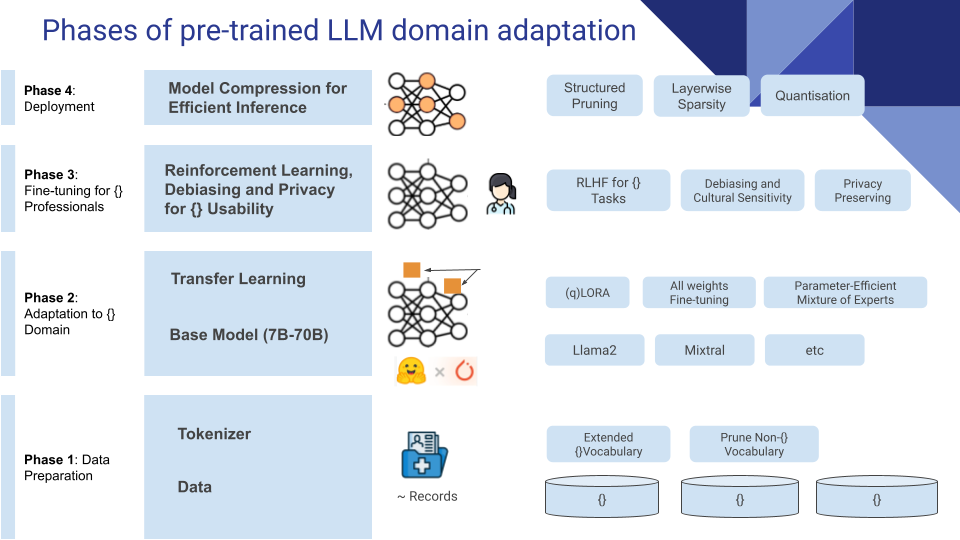
Components of the standard Pipeline
Within the training and inference pipelines, we often see work around Data, Context, Model, Controllable Generation, Prediction Tasks and Evaluation. These are the columns in the chart below.
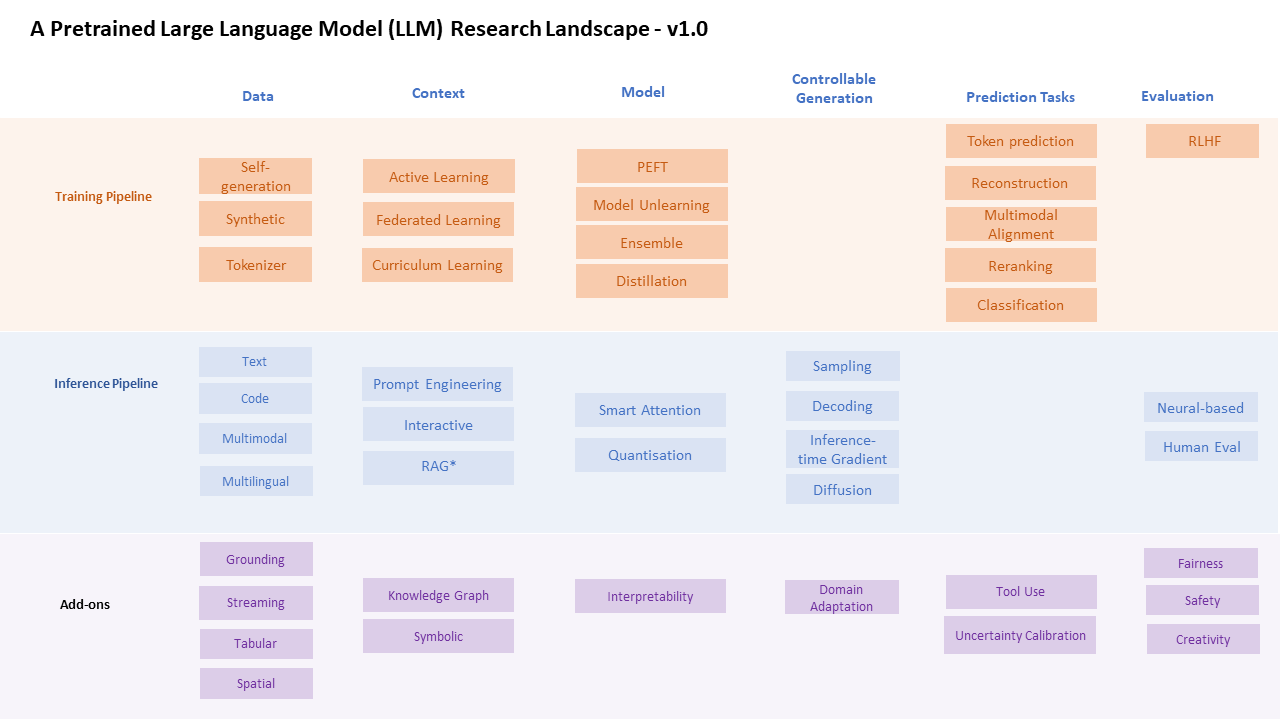
You can also download this as a pptx.
I recently plugged and played the components for a hackathon-ish slide illustrating the phases of LLM domain adaptation. I used this for medical originally (hence the emphasis on privacy and what not) but the phases are generalisable to any domain. Some time spent working in the domain is necessary to build an intuition of what components of the models need more tuning and what is fine to just use off-the-shelf pre-trained LLMs.