Monitoring Jobs on the Server
When we are running jobs on the grid, jobs can fall off unexpectedly and we always want to know what has died and why. Since we would typically submit tens of jobs, we need automated ways to track their progress.
A typical approach is to send ourselves an email when something fails. However this gets annoying quickly if we are iterating fast because we have to unlock the phone, open the mail client, open the email, locate the job ID number, switch back to the work screen etc.
Another issue is if a job falls of the queue after it’s started to run. It’s either completed or some kind of nasty error (often memory error), and its a pain to figure out which it is because the job ID is now gone from
the list of currently running jobs on the server. Hence, we can’t simply run qstat -u $USER and find the job that died.
Instead the following is easy to set up with minimal infrastructure
- Use tqdm library so there is a progress bar for the main function.
- save error logs to
logs_e/*jobID, and normal logs tologs_o/*jobID - Log the command used to run the script to the first line of
logs_o/*jobID - Monitor all jobs continuously with this script.
# monitor_jobs.sh
start=$1
end=$2
while true; do
for jobID in `seq ${start} 1 ${end}`; do
if [ -e logs_o/*$jobID ]; then # it's your file
echo -n "$jobID>"; sed -n 1p logs_o/*$jobID # prints command used to run the job
cat logs_e/*$jobID # prints job progress
echo ""
fi
done
sleep 60
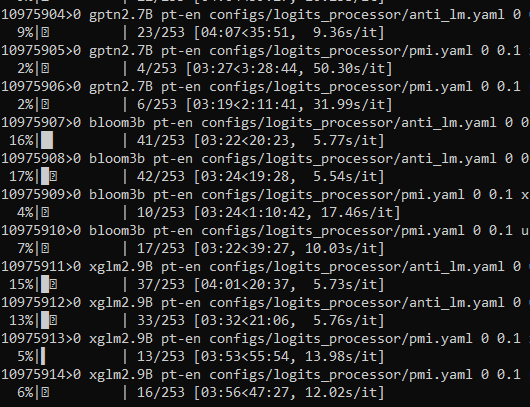
doneRight after I submit a bunch of jobs, I take note of the start and end of the job number, when
I submit another bunch of jobs, I might update the last job number. When we run bash
monitor_jobs.sh $startID $endID, we get something like this which gets updated every 60
seconds.