Is MCP a USB connector?
Preview
A lot of people talk about how MCP is a USB-C connector to Services and APIs on the internet. But I think this doesn’t really give people a proper appreciation of the picture, because it’s not that difficult to do integrations with REST-APIs or for LLM Agents to be exposed to functions directly without a client-server architecture.
Isn’t it straightforward to import googledrive and allow LLMs to go execute that function? Or to curl the API? Why do we need a new protocol?
First some Preliminaries
Here’s a workflow with MCP:
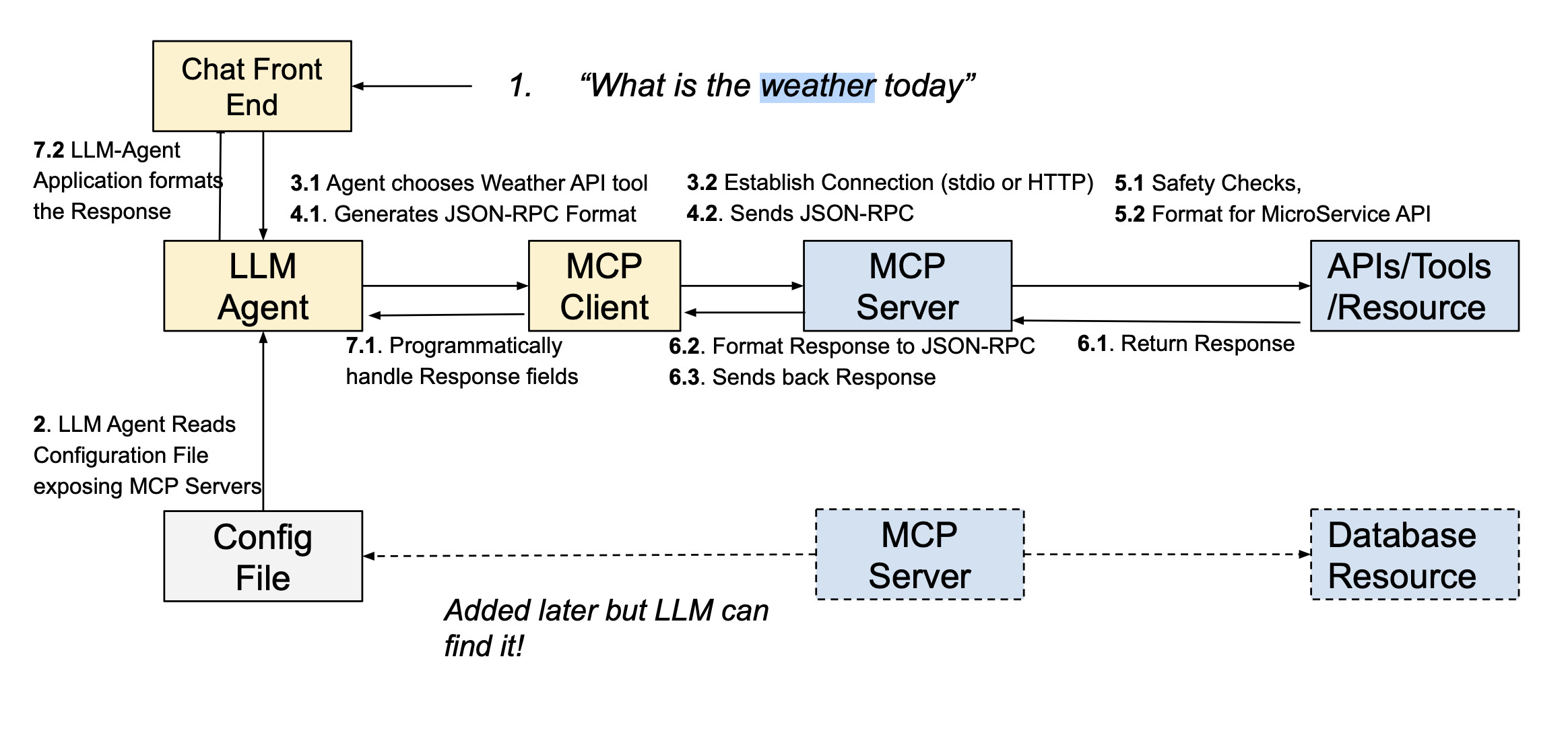
1) Human asks for the weather
2) Agent has a configuration file that tells it about available MCP servers
{
"mcpServers": {
"weather": {
"command": "python",
"args": ["/path/to/weather.py"],
"env": {}
},
"filesystem": {
"command": "node",
"args": ["/path/to/filesystem-server.js"]
}
}
}3) Agent spawns subprocess for local server OR establishes a connection to the remote Server
4) Agent generates and sends JSON-RPC to the server
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params":
{
"name": "get_alerts", "arguments": {"state": "CA"}
}
}5) MCP Server processes and forwards query to the API or function call
6) External Tool or API returns a response and MCP Server formats this as JSON-RPC
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"content": [
{
"type": "text",
"text": "Active alerts for CA:\nHeat Warning: Excessive heat..."
}
]
}
}7) LLM-Agent Application formats the response
What MCP is about
We want to give LLM-Agents the ability to execute functions to overcome their limitations.
But this is ridiculously dangerous. If you give code execution control to an LLM or allow it to access an SDK (e.g., allow it to do code.eval()), there must be endless checks on what actually gets executed.
We might say that we only give Agents read access (GET, no POST), but sometimes we do want to let Agents have some write access if we know those can happen reliably. Meaning, we need to control the kinds of write access they have gradually. The entire Google Drive API which has been exposed to human programmers may be more than what we’d like an LLM to be able to execute.
Hence a LLM-safe-access wrapper needs to be constructed to expose a subset of the full APIs and SDKs that we are prepared for Agents to hit.
Why not just have some piece of code that exposes only the “llm-safe” functions ?
That’s akin to a local MCP server, but using stdio as a transport protocol.
But why do we need to set up this stdio and separate client and servers. Can’t we directly expose these “llm-safe” functions to the Agent?
Technically we can, and that’s what LangGraph did for exposing Tool Calls for a while (I’m not sure if they still do). The main advantage of setting up server-client architecture, is for applications to be language agnostic so that different programming languages can be used at different parts of the stack. For e.g., we may want the front end to be completely written in node, while the backend is in Python.
For LLM-providers doing agentic workflows at the backend, being language agnostic is really important because Claude might be optimised in Rust or C++ for performance, while the majority of the API callers use Node or Python.
What is this stdio, why isn’t the MCP client sending messages over HTTP via REST API to a server?
It just depends if we are calling locally, or across machines over a network. If claude is calling MCP servers by spinning up subprocess, this has less overhead of spinning up a Web Server listening for HTTP Requests.
However, I think for most people it is easier to always spin up a web server for the MCP Server, as this is a general solution for MCP Servers on local machines, and MCP servers across a network. It does matter if we are trying to squeeze performance and avoiding the HTTP Overhead.
What’s JSON-RPC?
JSON-RPC is programming language neutral, there’s a lot of JSON on the internet, and LLMs are great at generating JSON.
Recall at Step 3. Claude generates and sends the JSON-RPC message itself, this is not generated by human code (altho it can be aided with prompt template).
JSON-RPC itself is a specification and standard that goes back to 2000s and was last updated in 2013. It’s a good idea for MCP to adopt this industry standard, because it is well-tested. (It even has pre-defined error codes.)
Why do we need this specification. Couldnt LLM Agents just handle whatever the Response is as long as it’s a JSON object.
They could.. But it’s an additional LLM-postprocessing-call on every tool call, just to do formatting over whatever the JSON object is.
What MCP is really about
Hence, I think what MCP is really about is educating AI Engineers about using JSON-RPC 2.0 Standard, so that at their backend, Anthropic does not need to do additional backend LLM-post-tool-call-processing, and can handle the fields programmatically.
Same for the input signature. Technically the client could query for the input schema that the server expects at each time, and then a LLM-preprocessing-call formatting to this specific input schema, but we’d rather save on LLM-runtime and handle this in actual code.
LLM providers and us can use any specification, as long as it provides sufficient coverage over all the use-cases.
What’s wrong with MCP
There’s nothing that wrong with MCP, I think people’s dissatisfaction with it just stems from the fact that it is not the final and complete solution of A2A protocol and so it falls below their expectation.
The basic concept exposes APIs to agents safely (and so Anthropic can have some predictability over the response signature), but if we wanted to use this in production, there’s a lot of things missing like the versioning for backward compatibility, guidelines on how to structure the data, separate fields for LLM agent vs display items, authentication, type checking … All the things that Software Engineers deal with when designing and working with APIs.
MCP was announced in a “hobbyist” state - it is designed for quick uptake, and people extend the API contract if they need to. For instance, there are multiple frameworks building on top of MCP to bridge the gaps. For instance, FastMCP supports HTTP authentication with JWT tokens, swag documentation via FastAPI and type checking via Pydantic.