High variance in RL (and how to measure it)
Summary
Policy Gradient algorithms in RL are known to have ‘high variance’, leading to a family of algorithms and 1000 of papers across more than 10 years (Actor-Critics, PPO, DPO, GRPO), clipping tricks, normalisation tricks, learning rate warm up tricks, which all attempt to reduce this variance.
To examine this variance, we’ll implement Policy Gradient from scratch and collect the gradients by pytorch hackery.
Implementing Policy Gradient From Scratch
The derivation of the objective function for Policy Gradient, is the following:
\[J(\theta) = E_{s,a} [ \log \pi_{\theta} (a \mid s) \cdot r (a \mid s) ]\]See this earlier writeup for the derivation.
In code, this translates to:
episode_loss = -(episode_returns * torch.stack(action_log_probs)).sum()
import numpy as np
from tqdm import tqdm
import torch
import torch.nn.functional as F
from pg_algo_base import PolicyGradientBase
class VanillaPolicyGradient(PolicyGradientBase):
def __init__(self, nactions, nstates, actor, learning_settings, early_stop_settings):
self.early_stop_settings = early_stop_settings
self.actor = actor
self.discount_factor = learning_settings['discount_factor']
self.max_episodes = learning_settings['max_episodes']
self.init_episodic_buffer()
self.init_progress_buffer()
def training_loop(self, env, seed_value=0):
for episode in tqdm(range(self.max_episodes)):
state, info = env.reset(seed=seed_value)
terminated, truncated = False, False
self.init_episodic_buffer()
# Monte-carlo rollout
while not terminated and not truncated:
state_tensor = torch.FloatTensor(state)
action, log_action_probs = self.actor.get_action_from_policy(state_tensor)
new_state, reward, terminated, truncated, info = env.step(action)
self.episodic_buffer['rewards'].append(reward)
self.episodic_buffer['states'].append(state)
self.episodic_buffer['log_action_probs'].append(log_action_probs)
state = new_state
self.progress_buffer['reward_per_episode'].append(sum(self.episodic_buffer['rewards']))
returns = self.compute_returns(mode='discounted')
episode_loss = -(returns * torch.stack(self.episodic_buffer['log_action_probs'])).sum()
# Optimization step
episode_loss.backward()
self.actor.optimizer.step()
self.actor.optimizer.zero_grad()Prelminary Learning Runs
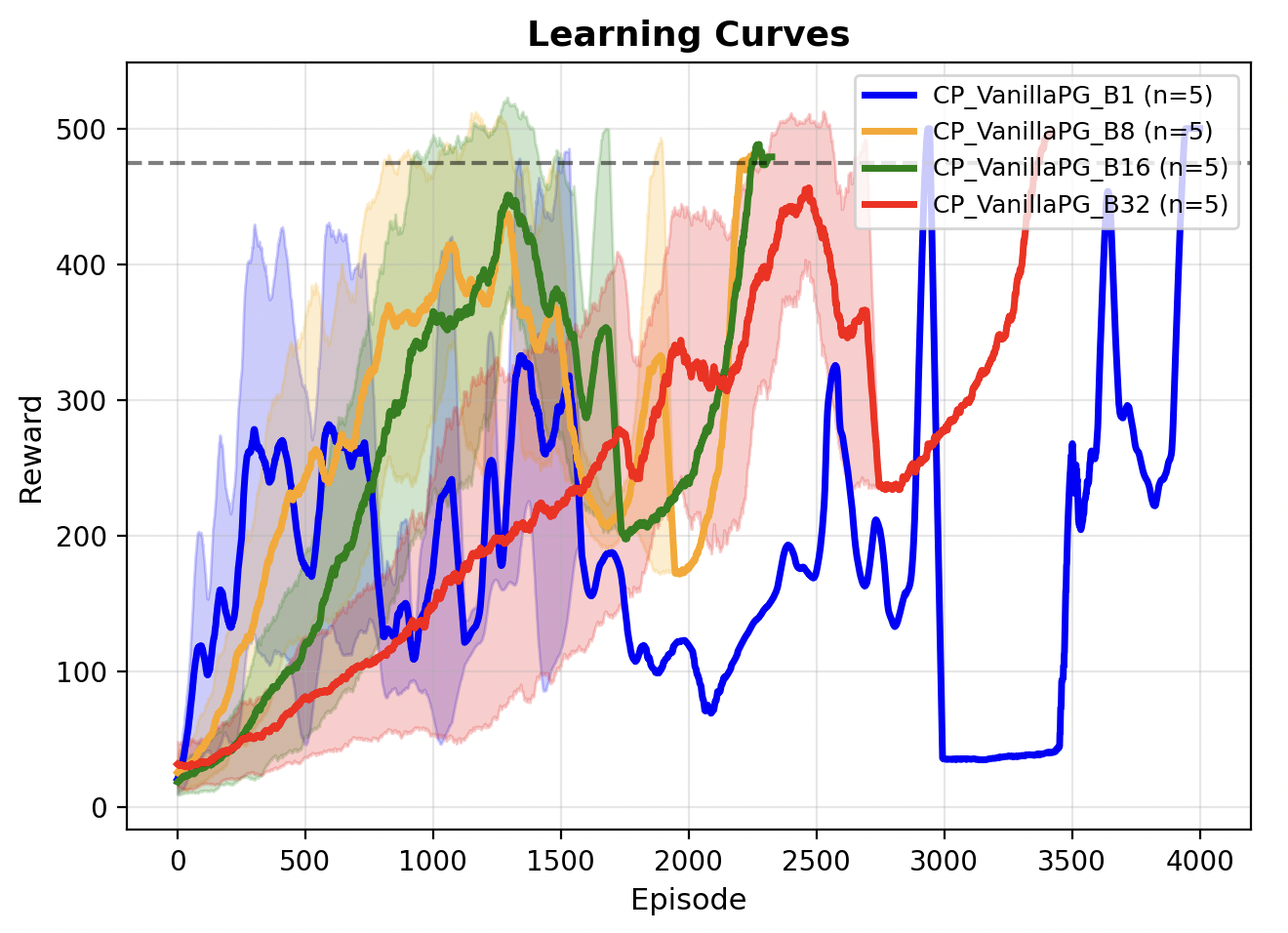
I ran this across 5 random seeds on CartPole (gymnasium). Looking at the Learning Curve, we did train our model (verified by replay), but the learning process was very shaky / unstable, and inconsistent across random seeds.

Gradient Health Check
Let’s take a look at the gradients over time. A large gradient norm is a sign of instability and potentially having a signal swinging in different directions. We can compute the grad_norm and the grad/weight ratio for each update, inserting that in between an optimizer step and zeroing out the gradient.
episode_loss.backward()
self.actor.optimizer.step()
# place update here
update_stats = self.actor.compute_model_grad_stats()
self.actor.optimizer.zero_grad()
self.progress_buffer['grad_norm_per_update'].append(update_stats['grad_norm'])
self.progress_buffer['gradw_ratio_per_update'].append(update_stats['gradw_ratio'])The gradient norm per update is very large ($10^4$)!, and so is the gradient / parameter weight ratio $>1$, which indicates that our model weights have exploded and the gradient is swinging the model weights around drastically with every update step.
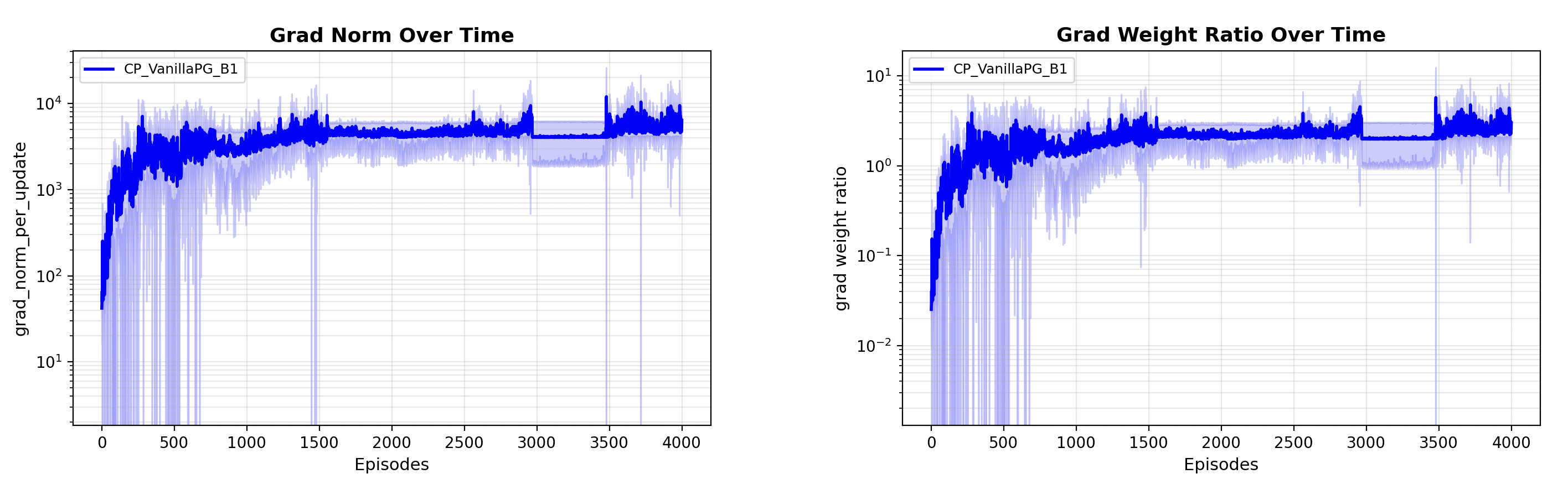
A naive way to handle this is by clipping gradients, so that updates are small. However we want to try some algorithmic improvements on top of the Vanilla Policy Gradient. Also, our learning rate is pretty reasonable, 0.005 so we shouldn’t be trying to change that.
These are the kind of gradient oscillations we don’t really encounter in supervised fine-tuning, because of the longer horizon rewards instead of the immediate reward (supervised signal).
What is “High Variance”
We can obviously see high magnitude, but what is “high variance”? The variance of a gradient signal, means that given the same state, the same fixed parameters of the policy network, we have wildly different reward signals -> which translates to wildly different gradient signals. This is due to stochasticity in the environment.
We can measure this by doing $n$ episodes with no gradient updates between episodes. I.e., we always start at the beginning of the environment.
Introducing a batch_buffer
We introduce a batch_buffer which tracks learning statistics across a batch of episodes for which we can calculate the variance across multiple episodic rollouts (keeping the same model parameters).
self.batch_buffer['episode_returns'].append(returns)
self.batch_buffer['log_action_probs'].append(self.episodic_buffer['log_action_probs'])
if (episode +1) % batch_size == 0:
for i in range(batch_size):
returns = self.batch_buffer['episode_returns'][i]
log_action_probs = self.batch_buffer['log_action_probs'][i]
episode_loss = -(returns * torch.stack(log_action_probs)).sum()
self.batch_buffer['losses'].append(episode_loss)
grad_var = self._get_var(self.batch_buffer['losses'], self.actor.network)
self.progress_buffer['grad_var_per_update'].append(grad_var)Measuring Variance due to Environmental Stochasticity
To calculate the gradient variance (self._get_var() in the code above), we need to do something like call episode_loss.backward(), get flattened gradients, and then do a model.zero_grad() so that our next fetching of gradient vectors is not affected. We then get variance of each node/dimension, across the episodes, and take the average variance across all dimensions.
flat_grad_vectors = []
for j in range(len(batch_losses)):
batch_losses[j].backward()
flat_grad_vectors.append(self.get_flatten_grad(model))
model.zero_grad()
# variance across episodes and across dimensions
grad_var = torch.stack(flat_grad_vectors).var(dim=0).mean()
return grad_var.item()However, since we have already called .backward(), and model.zero_grad(), we lose the gradient information for the optimizer step. Hence we are going to hack around this and insert the gradient back manually.
grad_avg = torch.stack(flat_grad_vectors).mean(dim=0)
idx = 0
for p in model.parameters():
numel = p.numel()
p.grad = grad_avg[idx : idx + numel].view(p.shape)
idx += numelWe plot the gradients over time for batch size 8, 16, 32, and see that they are just incredibly high indicating that the learning signal is not stable across different rollouts.
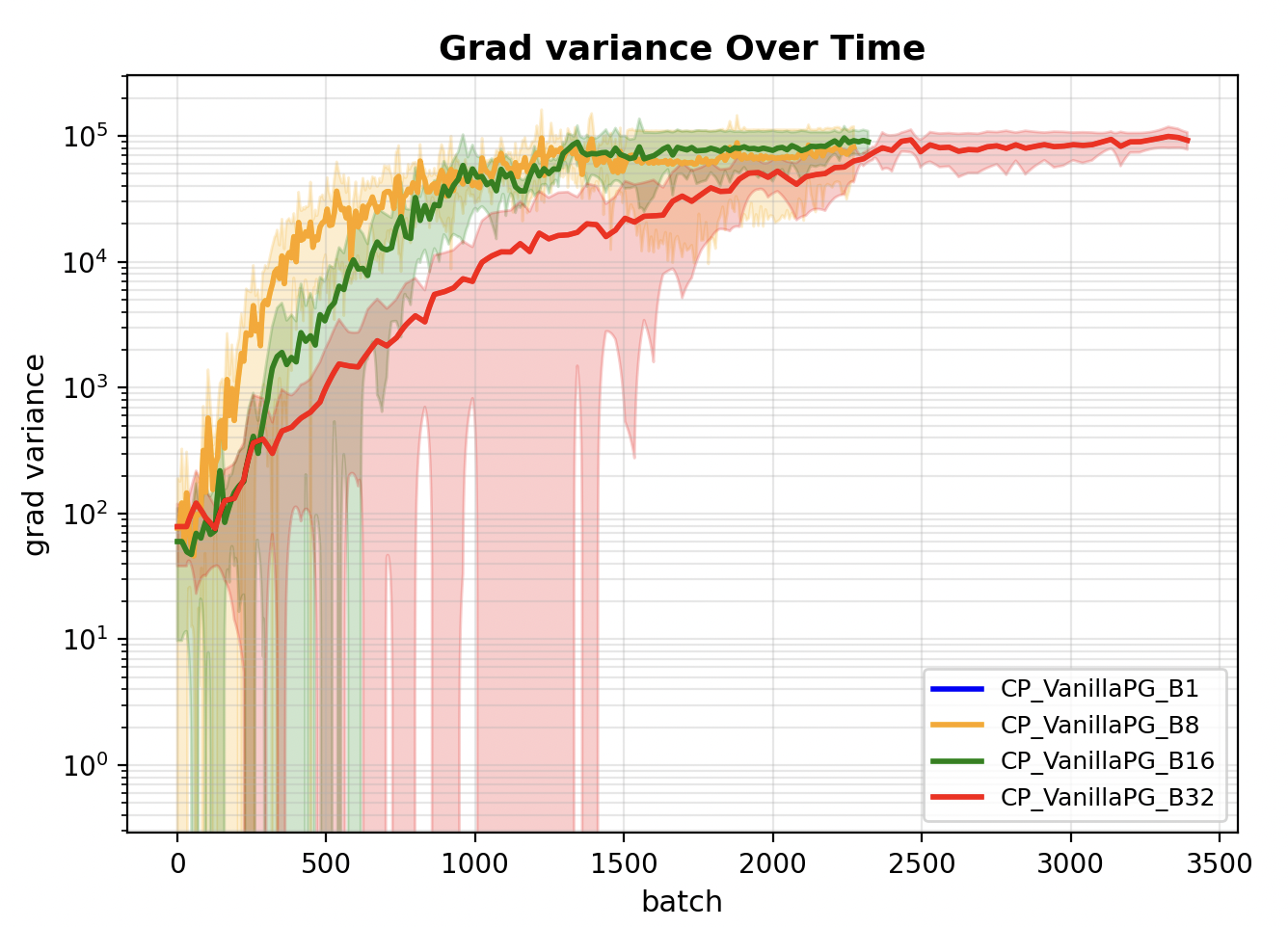
Note that batch size 1 is missing from above plot as for one episodic roll out, we cannot straightforwardly observe the gradient’s variance, especially with continuous states. If the states were discrete, then it might be possible to observe the variance in gradient signals for each discrete state at the end of a single rollout, if the environment states are highly repeatable like in a grid world.
Effect of Different Batch Sizes
Observe that across various batch_sizes 1, 8, 16, 32. The gradient variance decreases with increasing batch_size, which means we are getting more stable training by increasing the batch_size. However there is a trade-off in terms of how many episodes we have to wait for an update. The good news is that in practice each of these episodes can be run in parallel because the model weights are frozen.

From the Learning Runs, 16 (green curves) is a good choice of a batch size which has lower gradient variance, and also updates faster than others such that we can solve the environment with fewer episodes.
Summary
We can measure gradient variance in RL, by isolating the environment stochasticity with multiple rollouts starting from the same network weights and starting state. Applying batch updates and combining multiple episodes for the gradient step is much more stable than doing single episode updates. However we see that larger batch size is not always better, as it is less sample efficient than smaller batches.
Even under the batched episodes update scheme, the gradient variance is still very large, which is addressed by various approaches to normalising the reward signals (Actor-Critic, PPO or GRPO).
Some Implementation Notes (Code Appendix):
-
The
episode_lossis a.sum()across timesteps, not a.mean()because we dont want to average rewards across long episodes. We want the rewards from long running successful episodes to be high. -
We’ll need an
episodic_bufferbecause we do computations on the monte-carlo rollout, and aprogress_bufferto track overall training progress after we clear theepisodic_buffer. -
The
PolicyGradientBasethat I’m inheriting is just a helper class that handlesinit_progress_buffer()andinit_episodic_bufferto keep the code clean. -
In practice, we do Early Stopping Checks but leaving out those details for now.
Standard Implementations
(Nothing new or special here.)
To Compute discounted returns
def compute_returns(self, mode='discounted'):
if mode == 'discounted':
returns = []
G = 0
# Compute discounted returns in reverse
for r in self.episodic_buffer['rewards'][::-1]:
G = r + self.discount_factor * G
returns.append(G)
returns.reverse()
return torch.tensor(returns, dtype=torch.float32)Compute Model Gradient Stats:
def compute_model_grad_stats(self):
weight_norms = []
grad_norms = []
for p in self.network.parameters():
if p.grad is not None:
# l2 norm of each tensor
grad_norms.append(p.grad.detach().pow(2).sum())
weight_norms.append(p.detach().pow(2).sum())
total_grad = torch.sqrt(torch.sum(torch.stack(grad_norms)))
total_weight = torch.sqrt(torch.sum(torch.stack(weight_norms)))
ratio = (self.lr * total_grad) / (total_weight + 1e-8)
return {
"grad_norm": total_grad.item(),
"weight_norm": total_weight.item(),
"update_ratio": ratio.item()
}Get Action from Policy
def get_action_from_policy(self, state):
action_probs = F.softmax(self.network(state), dim=-1)
action = torch.distributions.Categorical(action_probs).sample()
log_action_probs = torch.log(action_probs[action])
return action.item(), log_action_probs