Clean TreeLSTMs implementation in PyTorch using NLTK treepositions and Easy-First Parsing
Overview
Tree LSTMs generalise LSTMs to tree-structured network topologies. Compared to sequence models which consider words as they appear in temporal order (or in the reverse direction), tree-structured models compose each phrase from its subphrase according to the given syntatic structure.
Tree LSTMs are conceptually straightforward extension of RNN-LSTMs but need a fair bit of thought to implement. Here’s what we need:
- A parser (takes in a sentence and outputs the parse tree structure).
- Stanford Core NLP/your own parser
-
Given the parse tree structure which implicitly contains how the word units should be progressively combined, convert this into a series of instructions which explicitly describes how the words should be combined.
- Write a RNN that takes in a series of instructions on how to combine a list of inputs. This strategy is inspired by stack LSTMs (Dyer et al., 2015) and Easy-first parsing(Kipperwasser and Goldberg, 2016). The key advantage of the latter approach is that we can access any element of the ‘stack’ (therefore it is no longer a stack).
1. Parser
- Download Stanford CoreNLP (2018 onwards) into your working directory.
- Write a script called
ParserDemo.java, which reads in our text file and outputs the parses
import edu.stanford.nlp.simple.*;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.io.IOException;
public class ParserDemo {
public static void main(String[] args){
String text = "";
try {
text = new String(Files.readAllBytes(Paths.get(args[0])));
} catch (IOException e){
e.printStackTrace();
}
String[] sentences = text.split("\n");
for (String sent: sentences){
Sentence s = new Sentence(sent);
System.out.println(s.parse());
}
}
}A bash script to compile and run our Parser script.
cd stanford-corenlp-full-2018-10-05
javac -cp "*" ParserDemo.java
java -cp ":*" ParserDemo sents.txt > sents_parse.txtNow, the sentence “Papa ate the caviar with a spoon” becomes
(ROOT (S (NP (NN Papa)) (VP (VBD ate) (NP (DT the) (NN caviar)) (PP (IN with) (NP (DT a) (NN spoon)))) (. .))) “
We can visualise this with the nltk package
from nltk.Tree import tree
from nltk.treetransforms import chomsky_normal_form as cnf
parse = Tree.fromstring(p)
#print(parse)
cnf(parse)
parse.pretty_print()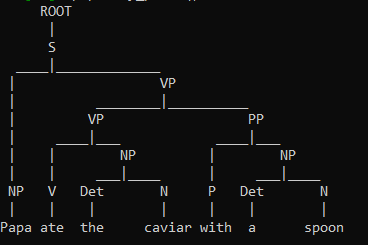
2. Converting the parse tree into a series of instructions
We build a Tree-LSTM from our understanding of how a standard RNN works. In contrast to the standard RNN which takes in the input from the previous time step, the tree-LSTM will take inputs from the hidden states of its child cell as described by the syntatic parse.
This implementation is heavily influenced by stack-reduce-parsing. However unlike stack-reduce which processes things sequentially from the stack, our instructions allow us to combine the current representations at every position of the stack.
We need to
- Maintain a stack with word and phrase representations to process
- Instructions on what to combine
- Update the stack accordingly
To extract the instructions, we rely on the nltk tree package. The cnf tree is encoded as a series of binary branching instructions, 0 indicates branch left and 1 indicates branch right. Based on the binary branching tree above, we can work out what each position refers to.
Taking the leaves as example:
- ‘Papa’: Left(0)-Left(0)-Left(0).
- ‘Caviar’: Left(0)-Right(1)-Left(0)-Right(1)-Right(1)-Left(0).
We can encode every tree position in this fashion.
leaves = parse.treepositions('leaves')
# [(0,0,0), (0, 1, 0, 0, 0), (0, 1, 0, 1, 0, 0), (0, 1, 0, 1, 1, 0), (0, 1, 1, 0, 0), (0, 1, 1, 1, 0, 0), (0, 1, 1, 1, 1, 0)]treepositions has parameters postorder and preorder, which corresponds to different types
of depth-first search. We use the pre-order search order for this implementation.
The buffer is given by tree.treepositions('postorder'). For each element in the buffer, if it
is a leaf, add it to the stack to process. If not, get the stack-positions of all its children, and replace the children on the stack with the parent element. After processing each non-leaf buffer element, increment a sequence of actions. The action sequence can either be unary(single element) or binary(tuple), which informs us which stack positions should be progressively fed as input to the neural network starting from the leaves(words).
def get_action_sequence(parse):
stack = []
seq = []
leaf_positions = parse.treepositions('leaves')
buffer = parse.treepositions('postorder')
for post in buffer:
if postn in leaf_positions:
stack.append(postn)
continue
child_pos = []
for i, s in enumerate(stack):
if s[:-1] == postn:
child_pos.append(i)
if len(child_pos)==1:
stack[i] = postn
seq.append(i)
else:
stack[child_pos[0]:(child_pos[1]+1)] = []
stack.insert(child_pos[0], postn)
seq.append(tuple(child_pos))
return seq
# [0, 1, 2, 3, (2, 3), (1, 2), 2, 3, 4, (3, 4), (2, 3), (1, 2), (0, 1), 0]3. Composing RNNs
Unlike standard RNN modules hich take in a sequence, we have to progressively combine inputs as specified by the action sequence, therefore all our RNN units are maintained at the cell level. The architecture consists of
- two identical LSTM cells for combining the child nodes of the tree.
- a final layer
- initialisation layers for hidden and cell units of LSTM
While looping over the action sequence, we update our stack after each action with the new input, hidden cell, lstm cell: (x, (hx, cx)), noting that beyond the leaf nodes, x is simply a zero tensor because we only need to consider hx as inputs to the next cell.
We also need to maintain the stack with update and delete actions the same way we did previously when getting instructions from the parse tree.
class ChildTreeLSTM(nn.Module):
def __init__(self, hidden_dim, device='cpu'):
# pass
super(ChildTreeLSTM, self).__init__()
self.hdim = hidden_dim
self.edim = 300
self.lstm = nn.LSTMCell(self.edim, self.hdim)
self.lstm2 = nn.LSTMCell(self.edim, self.hdim)
self.final_layer = nn.Linear(self.hdim, 1) # map from hidden layer to output
self.init_cx = nn.Parameter(torch.rand(1, self.hdim).cuda(device=device))
self.zero_x = torch.zeros(1, self.edim, requires_grad=False).cuda(device=device)
self.init_hx = torch.tanh(self.init_cx)
def forward(self, sent, action_sequence):
#initialize hx, cx
stack = []
hx = self.init_hx
cx = self.init_cx
for x in sent:
x = self.embedding(x)
x = x.view(1, x.shape[0])
stack.append((x, (hx, cx)))
for action in action_sequence:
if type(action)==int:
x, (hx, cx) = stack[action]
# unirule lstm cell needs to take in x, hx, cx
# after the first embedding has been read in, x is zero subsequently.
hx, cx = self.lstm(x, (hx, cx))
hx, cx = self.lstm2(x, (hx, cx))
stack[action] = (self.zero_x, (hx, cx))
if type(action)==tuple:
x0, (hx0, cx0) = stack[action[0]]
x1, (hx1, cx1) = stack[action[1]]
# combine hx0 and hx1
# combine x0 and x1
hx = hx0 + hx1
cx = cx0 + cx1
hx, cx = self.lstm(self.zero_x, (hx, cx))
hx, cx = self.lstm2(self.zero_x, (hx, cx))
stack[action[0]] = (self.zero_x, (hx, cx))
del stack[action[1]]
assert len(stack)==1
x, (hx, cx) = stack[0]
score = self.final_layer(hx)
return scoreIn this example we combine child cells by simply summing them together, but there are of course more sophisticated ways of combining cells by doing clever things with the gating mechanism of the LSTM (Tai et al., 2015).
References
Tai, K. S., Socher, R., & Manning, C. D. (2015). Improved semantic representations from
tree-structured long short-term memory networks. arXiv preprint arXiv:1503.00075.
Dyer, C., Ballesteros, M., Ling, W., Matthews, A., & Smith, N. A. (2015). Transition-based dependency
parsing with stack long short-term memory. arXiv preprint arXiv:1505.08075.
Kiperwasser, E., & Goldberg, Y. (2016). Easy-first dependency parsing with hierarchical tree LSTMs. Transactions of the Association for Computational Linguistics, 4, 445-461. arXiv preprint.